また一口メモ。
hdfsadmin -report は権限が必要なさそうだが、hadoopのsuperユーザー権限が必要。
デフォルトではhadoopユーザー。
2010年10月24日日曜日
2010年5月20日木曜日
/etc/hostsの罠
皆様お久しぶりです。
会社でHadoopのテスト環境を構築していたのですが、思いっきり、はまったのでPOSTしてみます。
Hadoop周りの各種設定ファイル(core-site.xml, hdfs-site.xml, mapred-site.xmlなど)の設定は一通り完了し、テスト環境なのでファイアウォールもSELinuxもオフにした状態で、start-all.shでHadoopを起動したのですが、namenodeにdatanodeが認識されません。ちゃんとそれぞれのホストでプロセスが動作しているにも関わらず、です。
色々試していくうちに次のことに気がつきました。
127.0.0.1:9000でListenしてやがる事が判明。
/sbin/ifconfig で 192.168.xxx.yyy のethが起動していることは確認できている、ということは・・・
/etc/hostsを開くと、案の定、
/etc/hostsからnamenode.FQDNとnamenodeを取り除くと正常に動作しました。
はぁ・・・。
関連リンクぅ~~
/etc/hosts 再び
会社でHadoopのテスト環境を構築していたのですが、思いっきり、はまったのでPOSTしてみます。
Hadoop周りの各種設定ファイル(core-site.xml, hdfs-site.xml, mapred-site.xmlなど)の設定は一通り完了し、テスト環境なのでファイアウォールもSELinuxもオフにした状態で、start-all.shでHadoopを起動したのですが、namenodeにdatanodeが認識されません。ちゃんとそれぞれのホストでプロセスが動作しているにも関わらず、です。
色々試していくうちに次のことに気がつきました。
- telnet namenodeホスト名 9000 では、Namenodeプロセスに接続されない
- telnet localhost 9000 では、Namenodeプロセスに接続される
- netstat -nl
127.0.0.1:9000でListenしてやがる事が判明。
/sbin/ifconfig で 192.168.xxx.yyy のethが起動していることは確認できている、ということは・・・
- ping namenode
> PING namenode.FQDN(127.0.0.1) 56(84) bytes of data.・・・・ /etc/hosts またおのれか
> (以下略)
/etc/hostsを開くと、案の定、
127.0.0.1 namenode.FQDN namenode localhost.localdomain localhostという記述が見つかりました。大きなお世話だっつーの・・・(ToT)
/etc/hostsからnamenode.FQDNとnamenodeを取り除くと正常に動作しました。
はぁ・・・。
関連リンクぅ~~
/etc/hosts 再び
2010年1月27日水曜日
MapReduce をJUnitでTDDで作る(10 さらにテスト追加)
こんにちは、yoshitsuguです。
前回からかなり時間が空いてしまいました。
今回はさらにテストを追加してみたいと思います。
(明らかなバグがあるので)
このプログラムの仕様をおさらいすると
というものでした。
現在実装済みのテストでは、
以下の場合を考えてみましょう
では、これを試すテストを追加して実施してみましょう。
テストはこのようになります。実行結果はどうなるでしょうか?
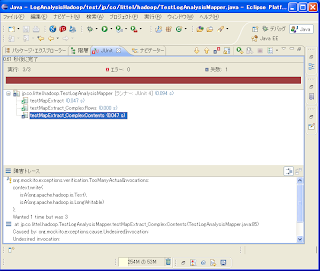
REDになりました。
これは、LogAnalysisMapperクラスのmap()メソッド内で、INFOがvalueに含まれているものを全て出力しているからです。仕様を満たすにはどうすればいいのでしょうか?
では実際にプログラムを書き換えてやってみます。
(上記の正規表現はそのままJavaのプログラムに貼り付けると’\’がエスケープシーケンスとして判別されてコンパイルエラーとなってしまいます。プログラム中は’\\’と記述すればコンパイルエラーは回避されます。)
map処理を以下のように書き換えました。
では実行してみます。どうなるでしょうか?

見事にGREENになりました。
今日はここまでにします。
前回からかなり時間が空いてしまいました。
今回はさらにテストを追加してみたいと思います。
(明らかなバグがあるので)
このプログラムの仕様をおさらいすると
ログの仕様:
yyyy-MM-dd hh:mm:ss,sss XXXX [PG名] @ [ログ出力内容]
要求仕様:
上記XXXX=INFOのものを抜き出して出力する。
というものでした。
現在実装済みのテストでは、
String[] lines = {を入力データとして使っていますが、実はこれだけではテストが足りていません。
"2009-12-14 00:00:26,340 INFO hogehoge @ abcdefg hijklmn opqrstu",
"2009-12-14 00:00:26,341 WARN fugafuga @ 11111111111111111111111",
"2009-12-14 00:00:26,341 ERROR fatal @ exception has occurred",
};
以下の場合を考えてみましょう
String[] lines = {この場合、2行目、3行目のログの種別はWARNとERRORなので、抽出されてはいけない筈です。
"2009-12-14 00:00:26,340 INFO hogehoge @ INFO=abcdefg hijklmn opqrstu",
"2009-12-14 00:00:26,341 WARN fugafuga @ INFO :11111111111111111111111",
"2009-12-14 00:00:26,341 ERROR fatal INFO = exception has occurred",
};
では、これを試すテストを追加して実施してみましょう。
/**
* 抽出する行のログの中身にINFOを含む場合
* @throws Exception 例外発生時
*/
@Test
public void testMapExtract_ComplexContents() throws Exception {
String[] lines = {
"2009-12-14 00:00:26,340 INFO hogehoge @ INFO=abcdefg hijklmn opqrstu",
"2009-12-14 00:00:26,341 WARN fugafuga @ INFO :11111111111111111111111",
"2009-12-14 00:00:26,341 ERROR fatal INFO = exception has occurred",
}; map(lines);
verify(context, new Times(1)).write(new Text(lines[0]), new LongWritable(1));
verify(context, new Times(1)).write(any(Text.class), any(LongWritable.class));
}
テストはこのようになります。実行結果はどうなるでしょうか?

REDになりました。
Wanted 1 time but was 3となっています。writeメソッドが1回しか呼ばれない想定なのに3度も呼ばれたということです。
これは、LogAnalysisMapperクラスのmap()メソッド内で、INFOがvalueに含まれているものを全て出力しているからです。仕様を満たすにはどうすればいいのでしょうか?
ログの仕様:とあるので、"^[\d]{4}-[\d]{2}-[\d]{2}\s[\d]{2}:[\d]{2}:[\d]{2},[\d]{3}\sINFO\s.*"の正規表現にマッチするものを出力するとすれば良さそうです。
yyyy-MM-dd hh:mm:ss,sss XXXX [PG名] @ [ログ出力内容]
要求仕様:
上記XXXX=INFOのものを抜き出して出力する。
では実際にプログラムを書き換えてやってみます。
(上記の正規表現はそのままJavaのプログラムに貼り付けると’\’がエスケープシーケンスとして判別されてコンパイルエラーとなってしまいます。プログラム中は’\\’と記述すればコンパイルエラーは回避されます。)
map処理を以下のように書き換えました。
/**
* map処理を実行します。
* @param key キー
* @param value 値
* @param cotext コンテクスト
*/
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// if (value.toString().contains(INFO)) {
if (value.toString().matches("^[\\d]{4}-[\\d]{2}-[\\d]{2}\\s[\\d]{2}:[\\d]{2}:[\\d]{2},[\\d]{3}\\sINFO\\s.*")) {
context.write(value, new LongWritable(1));
}
}
では実行してみます。どうなるでしょうか?

見事にGREENになりました。
今日はここまでにします。
2010年1月5日火曜日
あけましておめでとうございます
yoshitsuguです。
明けましておめでとうございます。
いや、仕事始めは昨日だったんだけれども。
クラウドコンピューティングがもてはやされてます。Hadoopはその中心的な技術のような扱いですね。
しかし、実は、私、Hadoopとクラウドの関係がいまいち解ってません。
大量データの処理がなんでクラウドコンピューティングと紐付くのでしょうか。
クラウドコンピューティングの大まかな定義は、
「『ネットの向こう側=雲の向こう側』で実行されるアプリケーション群を利用すること」
だと認識しています。
代表はGMail、GoogleDocumnent、GoogleAppEngine、AmazonEC2など。
広い意味ではWebMail系のWebアプリケーションも含まれるのでしょうか。
GoogleDocumentやGoogleAppEngineの裏側でGFSやBigTableやMapReduceが動いているのは理解できるのです。Yahoo.comやfacebookの裏側でHadoopが動いているのも理解できるのです。
だが、だからHadoop=Cloudだとはいえないと思うのです。
Hadoopをバックエンドで動かすシステムはいくらでも構築可能です。でもそれはクラウドコンピューティングとは違う。クラウド環境の構築は、何万アクセス何億アクセスにも耐えきれるネットワークインフラ、サーバーインフラの構築、使いやすいWebインターフェースの構築なくしてあり得ない。
いくらバックエンドにHadoopを用いても従来のままのWebサービスはクラウドコンピューティングではないのです。
日本でクラウドコンピューティングインフラをどうやって実現していくか?
世界の巨人たちに見劣りしないサービスをどうやって提供するか?
日本のIT会社がクラウドで食っていくためには、それを実現しなければお話にならないと思います。
「クラウドで食えるサービスづくり」
それが今年の私の目標です。
明けましておめでとうございます。
いや、仕事始めは昨日だったんだけれども。
クラウドコンピューティングがもてはやされてます。Hadoopはその中心的な技術のような扱いですね。
しかし、実は、私、Hadoopとクラウドの関係がいまいち解ってません。
大量データの処理がなんでクラウドコンピューティングと紐付くのでしょうか。
クラウドコンピューティングの大まかな定義は、
「『ネットの向こう側=雲の向こう側』で実行されるアプリケーション群を利用すること」
だと認識しています。
代表はGMail、GoogleDocumnent、GoogleAppEngine、AmazonEC2など。
広い意味ではWebMail系のWebアプリケーションも含まれるのでしょうか。
GoogleDocumentやGoogleAppEngineの裏側でGFSやBigTableやMapReduceが動いているのは理解できるのです。Yahoo.comやfacebookの裏側でHadoopが動いているのも理解できるのです。
だが、だからHadoop=Cloudだとはいえないと思うのです。
Hadoopをバックエンドで動かすシステムはいくらでも構築可能です。でもそれはクラウドコンピューティングとは違う。クラウド環境の構築は、何万アクセス何億アクセスにも耐えきれるネットワークインフラ、サーバーインフラの構築、使いやすいWebインターフェースの構築なくしてあり得ない。
いくらバックエンドにHadoopを用いても従来のままのWebサービスはクラウドコンピューティングではないのです。
日本でクラウドコンピューティングインフラをどうやって実現していくか?
世界の巨人たちに見劣りしないサービスをどうやって提供するか?
日本のIT会社がクラウドで食っていくためには、それを実現しなければお話にならないと思います。
「クラウドで食えるサービスづくり」
それが今年の私の目標です。
登録:
コメント (Atom)